ACE-TA, a new agentic teaching assistant, autonomously handles coding queries, quiz creation, and stepwise code tutoring by leveraging advanced Large Language Models. This innovative framework integrates precise Q&A, adaptive assessments, and interactive coding guidance to enhance programming learning. Its launch marks a significant leap in AI-driven education, promising more personalized and effective coding instruction. Next steps include broader adoption and real-world classroom testing to refine its impact.
AI & Machine Learning
ACE-TA Revolutionizes Coding Education
Sources (3)
More from AI & Machine Learning
-
Benchmarking AI Agents in Healthcare Admin
 research →
research →A new benchmark called HealthAdminBench has been introduced to evaluate AI agents on healthcare administration tasks, a sector with over $1 trillion in annual spending. The benchmark includes realistic GUI environments and 135 expert-defined tasks covering Prior Authorization, Appeals, and Durable Medical Equipment orders. Despite strong subtask performance, the best AI agent only achieved 36.3% task success, highlighting challenges in end-to-end reliability. This benchmark sets the stage for improving AI-driven administrative workflows in healthcare.
-
AI Agents Revolutionize Drug Discovery
 research →
research →AI agents are now capable of autonomously scouting and reverse-engineering complex software, accelerating drug discovery processes. Tools like MirrorCode showcase AI’s ability to reimplement thousands of lines of code without source access, highlighting rapid AI progress. This breakthrough promises faster development cycles in pharmaceuticals and biotech, with safety and ethical considerations guiding deployment. Industry leaders are watching closely as AI reshapes drug scouting and software innovation.
-
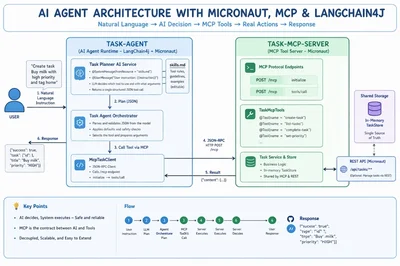
Building Practical AI Agents with LangChain4j
 research →
research →Developers are now creating AI agents that not only understand language but also perform real-world tasks autonomously. Using LangChain4j, Micronaut, and the Model Context Protocol (MCP), programmers can build Java-based agents that interpret instructions, decide on actions, and execute them seamlessly. This approach solves the challenge of connecting language models to tools reliably without cloud dependencies. The next step is adopting MCP servers widely to streamline AI automation across industries.
-
Run Vision AI Fully Offline on iPhone
 research →
research →Apple’s Neural Engine now powers vision AI models that run entirely on your iPhone without internet or accounts. The free open-source app Off Grid lets users analyze images, read documents, and get answers from photos locally, ensuring privacy and zero data upload. This breakthrough means powerful AI vision capabilities are accessible anywhere, anytime, without compromising security. Next, expect more apps to leverage this offline AI for enhanced privacy and convenience.
-
LLMs Must Master Human Empathy
 research →
research →A new study from April 2026 highlights that Large Language Models (LLMs) currently lack true human empathy, often distorting emotional and contextual nuances despite high benchmark scores. Researchers identify four key empathy failures—sentiment attenuation, granularity mismatch, conflict avoidance, and linguistic distancing—that undermine LLMs’ ability to faithfully represent human perspectives. This insight urges AI developers to integrate empathy-aware training and evaluation to ensure LLMs perform responsibly in sensitive, human-centered roles. The next step involves creating benchmarks and training signals that prioritize empathy alongside accuracy.
-
LLMs Struggle to Ignore Irrelevant Tools
 research →
research →Large language models (LLMs) often mistakenly invoke irrelevant tools due to a flaw called structural alignment bias, which causes them to activate tools whenever query attributes match tool parameters, even if the tool is useless. This discovery, detailed in the new SABEval dataset study, reveals a major blind spot in current AI evaluations. Understanding this bias is crucial for improving AI reliability and avoiding unnecessary tool calls. Researchers now aim to refine LLM decision-making by balancing semantic relevance with structural matching.
-
PepBenchmark Sets New Standard in Peptide AI
research →
PepBenchmark launches as the first unified benchmark for peptide machine learning, addressing a critical gap in drug discovery AI. It consolidates 35 datasets, a standardized preprocessing pipeline, and a leaderboard comparing top models, including GNN and PLM approaches. This breakthrough promises faster, more reliable peptide therapeutic development worldwide. Researchers and pharma companies now have a shared foundation to accelerate innovation and real-world applications.
-
Audio-Omni Unifies Sound Creation
 research →
research →Audio-Omni emerges as the first all-in-one framework that seamlessly integrates audio generation, editing, and understanding across sound, music, and speech. Developed with a novel architecture combining a frozen Multimodal Large Language Model and a trainable Diffusion Transformer, it tackles data scarcity with the new AudioEdit dataset of over one million editing pairs. This breakthrough outperforms specialized models and sets a new standard in audio AI. The next step is seeing how Audio-Omni transforms real-world audio applications and creative workflows.
-
CodaRAG Boosts AI Reasoning Power
research →
CodaRAG, a new AI framework inspired by Complementary Learning Systems, transforms retrieval-augmented generation by linking fragmented knowledge into coherent chains. Unlike traditional methods that treat evidence as isolated facts, CodaRAG actively navigates associative pathways to consolidate and prune information, improving retrieval recall by up to 10% and generation accuracy by up to 11% on GraphRAG-Bench. This breakthrough promises more reliable and precise reasoning in large language models, setting a new standard for knowledge-intensive AI tasks. Researchers are now exploring broader applications and integrations with existing retrieval systems.
-
New Framework Empowers Smarter AI Generation
research →
Researchers have unveiled a novel framework that enables even small Large Language Models (LLMs) to learn and enforce context-sensitive constraints automatically during text generation. This approach overcomes the traditional need for manual rule-setting, allowing models with just 1 billion parameters to outperform larger counterparts in producing valid, controlled outputs. The breakthrough promises more reliable AI-generated content and could reshape how LLMs are trained and deployed. Next steps include broader testing and integration into real-world applications to enhance AI reliability and safety.
-
New Training-Free Attack Exposes LLM Privacy Risks
research →
David Ilić and colleagues have introduced EZ-MIA, a powerful membership inference attack that requires no additional training and targets autoregressive language models. This method exploits error tokens where models mistakenly assign elevated probabilities to training data, revealing memorized sensitive information. The breakthrough improves detection rates at low false-positive levels, crucial for real-world privacy auditing. As large language models become ubiquitous, EZ-MIA highlights urgent privacy vulnerabilities and sets the stage for stronger defenses ahead.
-
Deep Learning Revolutionizes Decision Making
 research →
research →Deep learning is transforming how decisions are made under uncertainty by complementing traditional optimization methods. The new research by I. Esra Buyuktahtakin highlights frameworks that integrate AI with operations research to tackle complex, dynamic environments. This approach expands AI’s role beyond prediction to actionable decision support, promising advances in fields from healthcare to finance. Next steps include applying these models in real-world large-scale systems to validate their impact.
-
Brain Predictive Coding Unlocks Language
 research →
research →A breakthrough study by Congchi Yin and colleagues reveals how brain predictive coding can reconstruct language from fMRI data, decoding semantic information by anticipating future words. This advances beyond previous speech perception decoding by grounding language reconstruction in neurological theory. The findings could revolutionize brain-computer interfaces, enabling more natural communication for patients. Next steps involve refining these models for real-time applications.
-
Boosting LLM Safety at Inference Time
research →
Deliberative alignment promises deeper safety for large language models by transferring reasoning skills from stronger models. Yet, new research by Pankayaraj Pathmanathan et al. reveals a persistent alignment gap between teacher and student models, impacting both safety and utility. This gap highlights ongoing challenges in ensuring AI behaves safely during real-time use. Future work will focus on closing this gap to enhance trustworthy AI deployment.
-
LLM Features Clash with RL Trading Policies
research →
New research reveals that while large language models (LLMs) can generate predictive features for reinforcement learning (RL) trading agents, these features may fail under macroeconomic shocks. A study using a modular pipeline and prompt optimization showed valid signals with an Information Coefficient above 0.15, yet the augmented agent underperformed compared to price-only baselines during distribution shifts. This highlights a critical gap between feature validity and policy robustness, emphasizing the challenge of adapting AI trading strategies in volatile markets. Future work will focus on bridging this gap to enhance RL agent resilience.
-
Omnimodal AI Models Reveal Hidden Biases
 research →
research →A new study exposes significant demographic and linguistic biases in omnimodal language models that process text, images, audio, and video. While image and video tasks show relatively fair performance, audio-based tasks reveal stark disparities across age, gender, and language groups. These findings underscore the urgent need for comprehensive fairness evaluations as such AI systems become widespread in real-world applications. Experts warn that without addressing these biases, the technology risks perpetuating inequality across multiple modalities.
-
CheeseBench Tests AI on Rodent Tasks
research →
CheeseBench benchmark evaluates large language models on nine classic rodent behavioral neuroscience tasks, testing AI's ability to learn goals from text alone. The best model, Qwen2.5-VL-7B, scored 52.6%, outperforming random agents but still behind rodent baselines at 78.9%. This benchmark highlights AI progress in mimicking animal cognition and sets a new standard for neuroscience-inspired AI evaluation. Next, researchers aim to refine models to close the gap with biological intelligence.
-
Agent² RL-Bench Revolutionizes RL Training
research →
Agent² RL-Bench introduces a groundbreaking benchmark for reinforcement learning agents, challenging them with complex, multi-step tasks that go beyond simple linear tool use. Unlike previous benchmarks, it features directed acyclic graph puzzles requiring strategic navigation and tool chaining, pushing agents to demonstrate advanced reasoning and planning. This new standard exposes current limitations, with top models hitting just 37.2% accuracy, signaling a major leap needed in RL agent capabilities. Researchers now have a robust platform to drive next-gen AI training and evaluation.
-
Ethics in AI Coding: What Developers Must Know
 research →
research →AI coding agents have moved beyond experiments and are now integral to software development across companies worldwide. However, ethical guidelines lag behind, leaving questions about code ownership, bias, security, and credit unresolved. These issues are not theoretical—they manifest as subtle biases, security flaws, and attribution disputes in real projects. Developers need clear frameworks to navigate these challenges responsibly as AI-generated code increasingly shapes the digital landscape.